
 登錄
登錄
 注冊
注冊
一種基于時隙ALOHA的RFID系統防碰撞算法
1、引言
RFID射頻識別是一種非接觸式的自動識別技術,它通過射頻信號自動識別目標對象并獲取相關數據。典型的RFID系統主要包括兩部分:讀寫器(Reader) 和標簽(Tag)。
在射頻識別系統工作時,在讀寫器的作用范圍內,可能會有多個應答器(標簽)存在,這些應答器的數據同時傳送到讀寫器時出現沖突即數據碰撞,導致讀寫器無法讀出數據。現階段RFID系統應用中,基于TDMA的防碰撞算法目前有兩種:基于比特位的二進制搜索算法和基于時隙的ALOHA 算法。二進制搜索算法需要閱讀器能夠確定碰撞的準確的比特位置,這就需要閱讀器對所有標簽的準確的同步,而這種同步在實現時是困難的;ALOHA算法在應用中隨著標簽數量的擴大,性能將急劇惡化[2]。因此,本文提出了一種改進的基于時隙ALOHA的防碰撞算法, 通過限制響應標簽的數量,降低了沖突發生的可能性,提高了標簽的識別效率,有效解決了ALOHA算法的這方面的局限性。
2、現有的ALOHA防碰撞算法[3]
2.1 純ALOHA(pure-ALOHA)
ALOHA是多路存取中最簡單的方法,它是一種隨機接入算法,這種算法多采取“標簽先發言”的方式,即標簽進入讀寫器的閱讀區域就自動向讀寫器發送其自身的ID,隨即標簽和讀寫器間開始通信。在標簽發送數據的過程中,若有其他標簽也在發送數據,那么發生信號重疊從而導致完全沖突或部分沖突。讀寫器檢測接收到的信號來判斷有無沖突。一旦發生沖突,讀寫器就發送命令讓標簽停止發送,隨機等待一段時間后再重新發送以減少沖突。
純ALOHA存在的一個嚴重問題是數據幀F的發送過程中,沖突發生的概率很大,其沖突期為2F。理論上,純ALOHA算法的信道最大利用率只有18.4%。此外,RFID系統中標簽不具有載波監聽發現沖突的能力,只能通過接收讀寫器的命令來判斷有無沖突。
2.2 時隙ALOHA(Slotted-ALOHA)
Slotted-ALOHA算法是在純ALOHA算法的基礎上把時間分成多個離散時隙,標簽只能在每個時隙的分界處才能發送數據。這樣標簽或成功發送或完全沖突,避免了純ALOHA算法中的部分沖突,使沖突期減少一半,提高了信道的利用率,達到36.8%,使純ALOHA算法的兩倍。但是這種方法需要一個同步時鐘,使得讀寫器閱讀區域內所有標簽的時隙同步。
2.3 幀-時隙ALOHA(Framed-Slotted ALOHA)
Frame-Slotted ALOHA算法是在時隙ALOHA算法的基礎上把N個時隙組成一幀,標簽在每個幀內隨機選擇一個時隙發送數據。
3、改進算法
胡建赟等人[4]在分析RFID系統識別過程后,在固定時隙數量,不同數量應答器的情況下,將時隙的數量固定在25個,應答器的最大數量設為30個,得到了在25個時隙數時,系統中標簽數量大于一幀所含的時隙數時,識別成功率急速下降的結果。因此,本文提出的算法,通過制定一定的規則來限制響應閱讀器請求命令的標簽數量,以達到提高閱讀器的識別效率,降低識別所有標簽所使用的時隙數的目的。
本文算法通過比較標簽序列號的一部分比特位,以限制響應請求命令的標簽數。閱讀器向標簽發送比較的開始位、比較位的長度和比較的基準值。標簽收到這些數據后,將自己的部分序列號與規定的比較基準值相比較,若小于基準值,則該標簽響應閱讀器。例如,假設標簽的序列號為8位二進制數,比較的開始位是比特位5,比較位的長度是3,比較的基準值是1002。如有一標簽A的序列號為100111012,根據以上的比較信息,可知該標簽用來比較的序列號部分為“0112”,小于比較基準值1002,則標簽A響應閱讀器。若另有一標簽B的序列號為011010012,易知,該標簽將不響應閱讀器。
閱讀器的識別成功率在標簽數大于一幀所含時隙數時,大幅降低,所以,本文提出的算法并不是在任何時候都需要使用的。限制該算法使用的條件是發生沖突的標簽數與發送的標簽數的比率。如果,該比率大于參考值,則采用本文提出的算法,否則,所有的標簽都響應閱讀器。Tae-Wook Hwang等人[5]提出過以上類似的算法,他采用的比率概念是發生沖突的時隙數與一幀所含時隙數的比值,但本算法采用了完全不一樣的比率概念。仿真結果顯示,采用本文的比率概念后,所使用的時隙數比Tae-Wook Hwang等人的時隙數降低了將近20%。
式1表達了本算法中比率概念及比率與參考值之間的關系。
R=C/T≥γ (1)
其中,C是發生沖突的標簽數,T是發送的標簽數,γ是參考值,它決定了是否采用本文提出的算法來限制響應閱讀器的標簽數量。圖1所示的為算法流程圖。

圖1本文提出的算法的流程圖
4、仿真結果分析
在仿真過程中,設定了一幀所含的時隙數是256,比較位的長度是3,比較的基準值是1002,每次比較的開始位隨機產生。當R值大于等于γ時,采用本文提出的算法,限制響應閱讀器的標簽數;R值小于γ時,所有標簽響應閱讀器。在以上的條件下,本仿真實驗考察了γ在取不同值時,標簽數從1逐漸增加到1000,閱讀器識別所有標簽所使用的時隙數的情況。表1所示的為仿真實驗中的參數的取值情況。其中S0.5 ~ S1為仿真結果圖中不同參數下縱坐標對應的值。
表1 仿真試驗中的參數
|
N(一幀所含的時隙數) |
Tags(標簽數) |
γ(參考值) |
S(識別所有標簽所使用的時隙數) |
|
N=256 |
Tags=n (n=1,2…1000) |
γ =0.5 |
S0.5 |
|
γ =0.6 |
S0.6 | ||
|
γ =0.7 |
S0.7 | ||
|
γ =0.8 |
S0.8 | ||
|
γ =0.9 |
S0.9 | ||
|
γ =1(普通算法) |
S1 |
在第一個仿真中,γ(gamma)值分別取了:0.5、0.6、0.7、0.8、0.9、1,由式(1)可知,R的值必定是小于等于1的,當R等于1的時候,說明所有標簽都發生沖突,這種概率在實際情況下是很小的。從圖1的流程圖可知,當閱讀器計算得到R的值大于等于γ(gamma)時,將采用本文提出的算法,所以當γ(gamma)=1的時候,是永遠不會采用到本文提出的算法,也就是說,閱讀器在識別標簽的過程中,沒有使用本文的算法,即γ(gamma)=1的曲線對應的是普通算法情況下,閱讀器識別所有標簽所使用的時隙數。γ(gamma)分別取值0.5、0.6、0.7、0.8、0.9時的曲線,對應了使用本文提出的算法時,閱讀器識別所有標簽所使用的時隙數情況。從圖2可以看出,當標簽數達到600個左右的時候,普通算法所消耗的時隙數急速上升,而本文提出的算法的時隙數曲線變化斜率基本保持不變,并且當標簽數大于600以后,可以明顯地看出本文提出的算法所使用的時隙數比普通算法的時隙數少使用了很多,充分體現出本文提出的算法比普通算法優越。另外,從圖2也可以看到,當γ(gamma)=0.8且擁有大量標簽時,閱讀器識別所有標簽所使用的時隙數是最少的。從圖3可以非常明顯的看出,當標簽數=990時,γ(gamma)分別取0.5、0.6、0.7、0.8、0.9、1(普通算法)的情況下,γ(gamma)=0.8時,使用的時隙數最少,比采用普通算法少了大約1300個,降低了約41%左右。
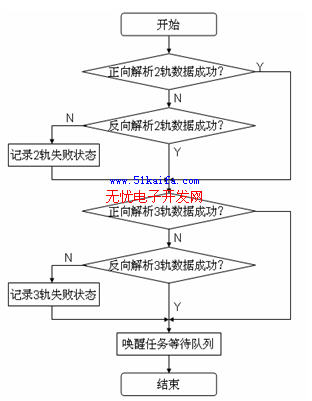
圖2 γ(gamma)取不同值時所使用的時隙數變化曲線
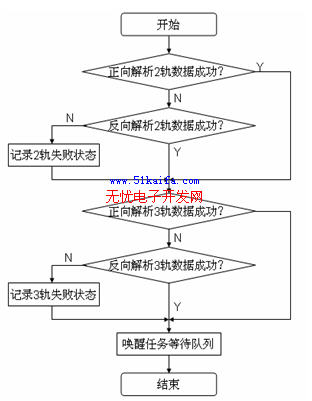
圖3 標簽數=990時,γ取不同值時所使用的時隙數比較
在第二個仿真中,一幀所含的時隙數(N)分別取256、128和64,并且在這三種情況下,分別使用了普通算法和本文提出的算法。目的是了解一幀所含時隙數的取值情況對閱讀器識別標簽過程中使用時隙數的影響,同時觀察本文提出的算法是否優越。從圖4可以看出,當N=256時,使用的時隙數最少。當N=128時,在標簽數大于300的情況下,應用本文提出的算法所使用的時隙數曲線的斜率約為5,而普通算法的曲線斜率約達到47,由此可知,后者的曲線增加速率約為前者的10倍,即所使用的時隙數隨著標簽數量的增加,其增加的速率在應用普通算法時約為應用本文算法時的10倍。當N=64時,也可以得到相應的比較情況。所以,通過第二個仿真試驗,驗證了本文提出的算法較之普通算法其性能是優越的。
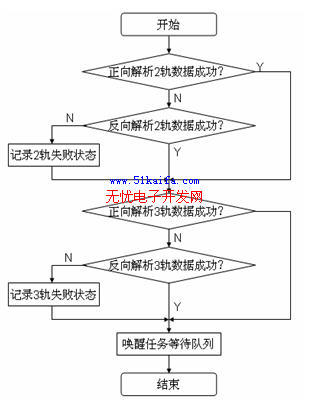
圖4 在一幀所含時隙數不同的情況下,應用本文提出的算法和普通算法時所使用的時隙數的比較
5、結論
本文作者創新點在于提出一種RFID系統防碰撞改進算法,該算法針對在RFID防碰撞算法中,ALOHA算法在應用中有隨著標簽數量的增加,性能急劇惡化的缺點,將沖突發生的比率與參考值γ相比較后,通過比較部分標簽序列號的方法,限制響應閱讀器的標簽數量,從而提高了識別標簽過程的性能。一系列的仿真結果顯示了本文所提出的改進算法比普通算法識別標簽所使用的時隙數少,性能優越。
參考文獻(References):
1、李寶山,射頻識別系統防碰撞技術的研究,包頭鋼鐵學院學報,2005.12
2、陳博,一種類二進制搜索的RFID系統反碰撞算法及其實現,電子器件,2006.3
3、陳香,張思東,薛小平,RFID防碰撞技術的研究,電腦與電信(PCCom),2006.4
4、胡建赟,李強,閔昊,時隙ALOHA法在RFID系統防碰撞問題中的應用,應用科學學報,2005.9
5、Tae-Wook Hwang,Byong-Gyo Lee, Young Soo Kim, Doug Young Suh and Jin Sang Kim, Improved Anti-collision Scheme FOR High Speed Identification in RFID System, Proceeding of the First International Conference on Innovative Computing, Information and Control,2006
6、胡圣波,鄭志平。一種井下RFID定位系統的讀卡器防碰撞算法[J]。微計算機信息,2006,9-2:185-187













